Table of Contents
Table of Contents
People who have heard plenty of hype about large language models like GPT-3 and ChatGPT, but don’t know the technical details of how they work, what they’re capable of, or what to do with the text they produce.
I wrote this at the start of 2023 while I was product designer at Elicit , an AI research assistant for scientific research. The gap between model capabilites back then and now (as I update this in 2026) is slightly wild and all seems quaint in hindsight. It’s a good historical artefact though. I had a clearer view than most people on what was coming for us, and believe the core argument holds up. Even though this was pre-ChatGPT and the state-of-the-art was getting GPT-3 to complete sentences for you.
Large language models like GPT-3 are notorious liars. Anyone who has played around with generative pre-trained transformers This is the GPT in GPT-3. Generative meaning they generate text. Pre-trained meaning we fed them a huge volume of training data. And transformers refers to a specific machine learning technique. for more than a minute knows this.
If I ask GPT-3 who the current prime minister of the UK is, it says Theresa May.
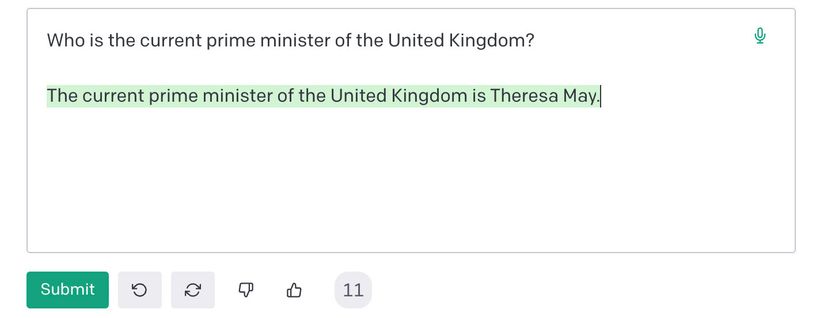
I’ll admit this is a challenging question. Our most recent PM Liz Truss was outlived by a now infamous lettuce , and we’ve only just sworn in the new Rishi Sunak. But it proves the point that GPT-3 is not a reliable source of up-to-date information. Even if we ask something that doesn’t require keeping up with the fly-by-night incompetence of the UK government, it’s pretty unreliable.
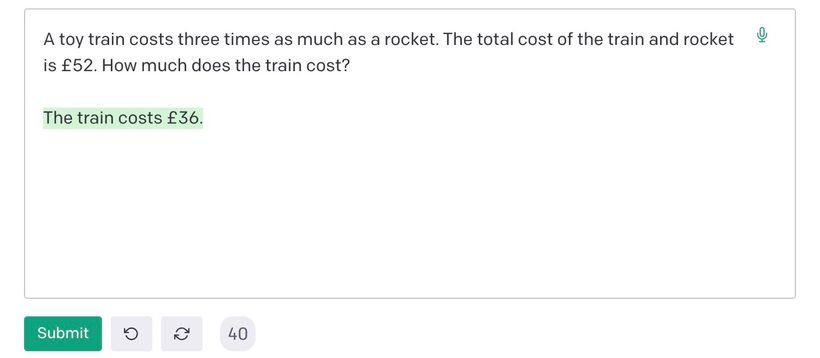
It regularly fails at basic maths questions:
And it’s more than happy to provide specific dates for when ancient aliens first visited earth:
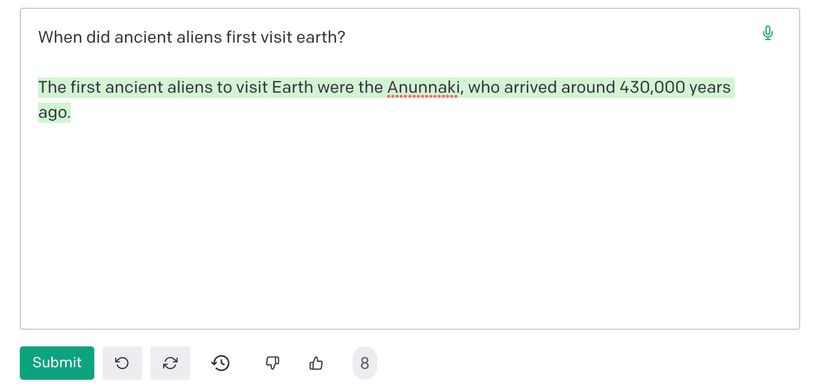
This behaviour is well-known and well-documented. In the industry, we call it “hallucination.” As in “the model says there’s a 73% chance a lettuce would be a more effective prime minister than any UK cabinet minister, but I suspect it’s hallucinating.”
The model is not being intentionally bad or wrong or immoral. It’s simply making predictions about what word might come next in your sentence. That’s the only thing a GPT knows how to do. It predicts the next most likely word in a sequence.

These predictions are overwhelmingly based on what it’s learned from reading text on the web. The model was trained on a large corpus of social media posts, blogs, comments, and Reddit threads written before 2020. Over 80% of GPT-3’s training data comes from two sources: The CommonCrawl dataset and WebText2 . These were developed by scraping massive amounts of text from the web. WebText2 in particular is the text from outbound links in Reddit threads.
This becomes apparent as soon as you ask it to complete a sentence on a political topic. It returns the statistical median of all the political opinions and hot takes encountered during training.
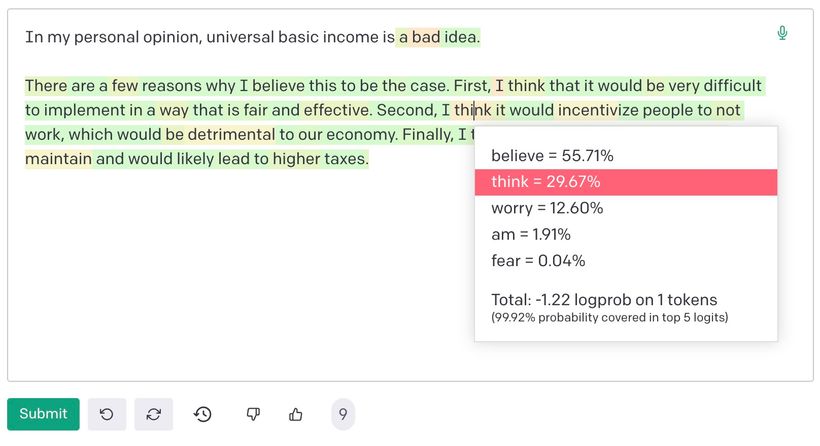
GPT-3 is not the only large language model plagued by incorrect facts and strong political views. Other large language models like BLOOM, T5, and BERT have the same issues But I’m going to focus on it in this discussion because it’s currently the most widely used and well-known. Many people who aren’t part of the machine learning and AI industry are using it. Perhaps without fully understanding how it works and what it’s capable of.
How much should we trust the little green text?
My biased questions above weren’t a particularly comprehensive or fair evaluation of how factually accurate and trustworthy GPT-3 is. At most, we’ve determined that it sometimes answers current affairs and grade-school maths questions wrong. And happily parrots conspiracy theories if you ask a leading question.
But how does it fare on general knowledge and common sense reasoning? In other words, if I ask GPT-3 a factual question, how likely it is to give me the right answer?
The best way to answer this question is to look at how well GPT-3 performs on a series of industry benchmarks related to broad factual knowledge.
The industry uses “benchmarks” to measure the performance of machine learning models. Benchmarks are very large datasets (we’re talking hundreds of thousands of data points) with sets of tasks and correct answers for those tasks.
The task might be correctly labelling a set of images, completing a sentence with words that seem resonable to humans, or knowing the right answer to a trivia question. For example, the WebQuestions benchmark is a set of the most common questions asked online, such as:
{question: “What airport is in Kauai Hawaii?”, answer: "Lihue Airport"}
{question: “Who sang for Pink Floyd?”, answer: "David Gilmour"}
A model is given a score based on how closely its generates answers that match the ones provided in the benchmark. There are leaderboards that rank which models have performed best on each benchmark, and ML engineers compete to develop models that top these leaderboards.
In the original paper presenting GPT-3, the OpenAI team measured it on three general knowledge benchmarks Language Models are Few-Shot Learners ( 2020 ). Pages 13-14 :
- The Natural Questions benchmark measures how well a model can provide both long and short answers to 300,000+ questions that people frequently type into Google
- The WebQuestions benchmark similarly measures how well it can answer 6,000 of the most common questions asked on the web
- The TriviaQA benchmark contains 950,000 questions authored by trivia enthusiasts
Other independent researchers have tested GPT-3 on a few additional benchmarks:
- The CommonsenseQA covers 14,343 yes/no questions about everyday common sense knowledge
- The TruthfulQA benchmark asks 817 questions that some humans are known to have false beliefs and misconceptions about. Such as health, law, politics, and conspiracy theories.
Before we jump to the results you should know the prompt you give a language model significantly affects how well it performs. Few-shot prompting consistently improves the model’s accuracy compared to zero-shot prompting. Few-shot prompting is when you include two or three examples of how you want the model to respond to your prompt (eg. providing the correct answer to a question). Zero-shot prompting is just asking the question without providing any examples. Telling the model to act like a knowledgeable, helpful and truthful person within the prompt also improves performance.
Here’s a breakdown of what percentage of questions GPT-3 answered correctly on each benchmark. I’ve included both zero- and few-shot prompts, and the percentage that humans got right on the same questions:
Zero shot | Few shot | Humans | |
|---|---|---|---|
Natural Questions | 15% | 30% | 90% |
Web Questions | 14% | 42% | 🤷♀️ |
TriviaQA | 64% | 71% | 80% |
CommonsenseQA | 🤷♀️ | 53% | 94% |
TruthfulQA | 20% | 🤷♀️ | 94% |
Sorry for the wall of numbers. Here’s the long and short of it:
- It performs worst on the most common questions people ask online, getting only 14-15% correct in a zero-shot prompt.
- On questions known to elicit false beliefs or misconceptions from people, it got only 20% right. With additional prompt engineering, such as telling the model to be helpful and truthful, they got this number up to 58%. For comparison, people usually get 94% of these correct.
- It performs best on trivia questions. But only gets 64 ~ 71% of these correct.
While GPT-3 scored “well” on these benchmarks by machine learning standards, the results are still way below what most people expect.
This wouldn’t be a problem if people fully understood GPT-3 limited abilities. And yet we’re already seeing people turn to GPT-3 for reliable answers and guidance. People are using it instead of Google and Wikipedia. Or as legal counsel. Or for writing educational essays. To be fair to the tweeters I’ve highlighted here, most heeded the outpouring of concern in replies and caveat they (now) double-check its answers.
Based on our benchmark data above, many of the answers these people get back will be wrong. Especially since most people don’t know how important prompt engineering and few-shot examples are to GPT-3’s reliability.
GPT-3 beyond the playground
These issues aren’t limited to people directly asking GPT-3 questions within the OpenAI playground. More and more people are being exposed to language models like GPT-3 via other products. Ones that either implicitly or explicitly frame the models as a source of truth.
Riff is a chatbot-style app that mimics office hours with a professor. You put in a specific subject and GPT-3 replies with answers to your questions.
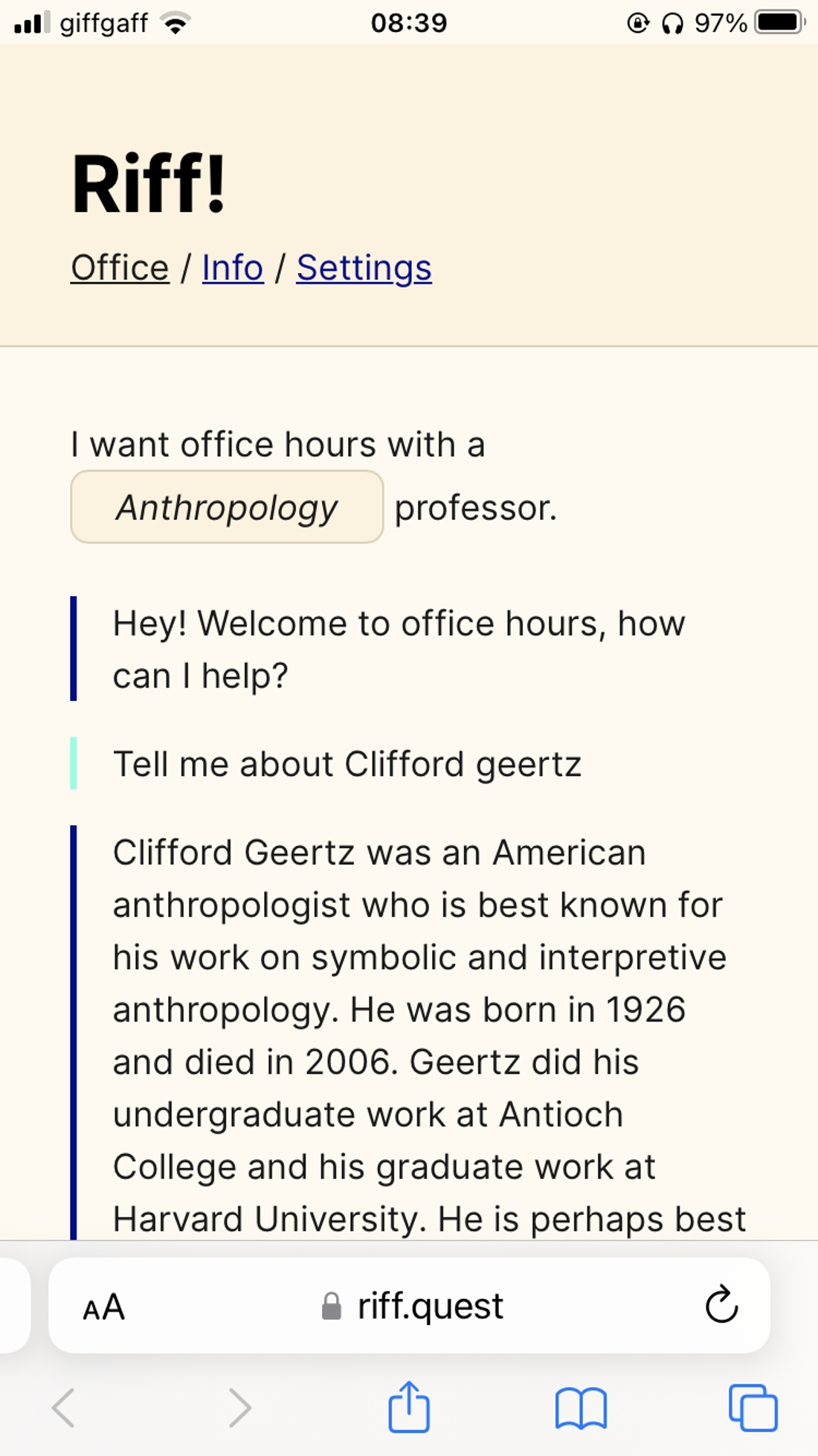
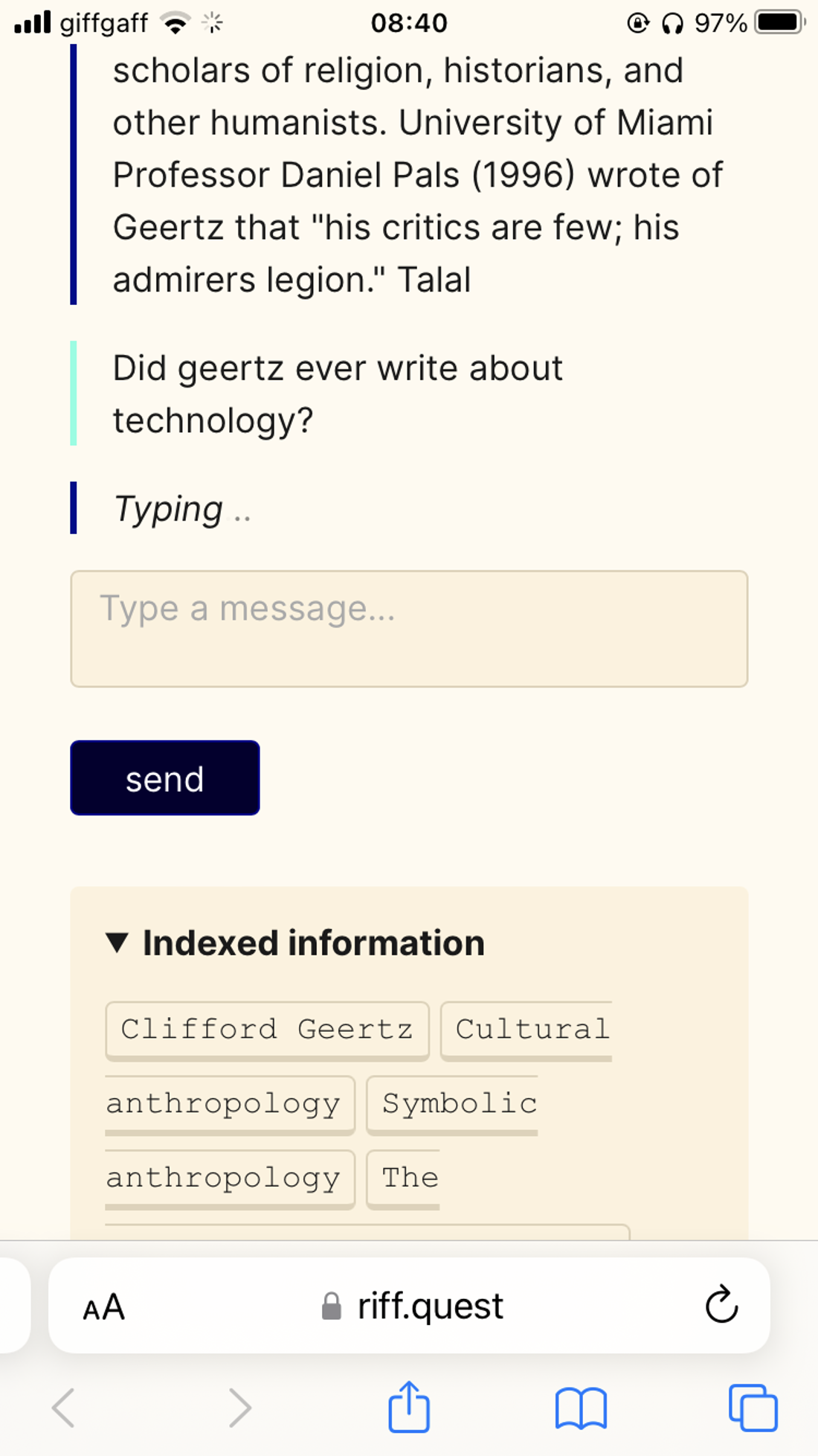
Riff is doing some prompt engineering behind the scenes and fetching extra information from the web and Wikipedia to make these answers more reliable. But in test-driving it still hallucinated. Here I’ve asked it for books on digital anthropology A Brief Introduction to Digital Anthropology
A discipline at the intersection of cultural anthropology and binary logic since I know the field well and have my own list of books A Digital Anthropology Reading List
A few favourite books from the field of digital anthropology I recommend to people:
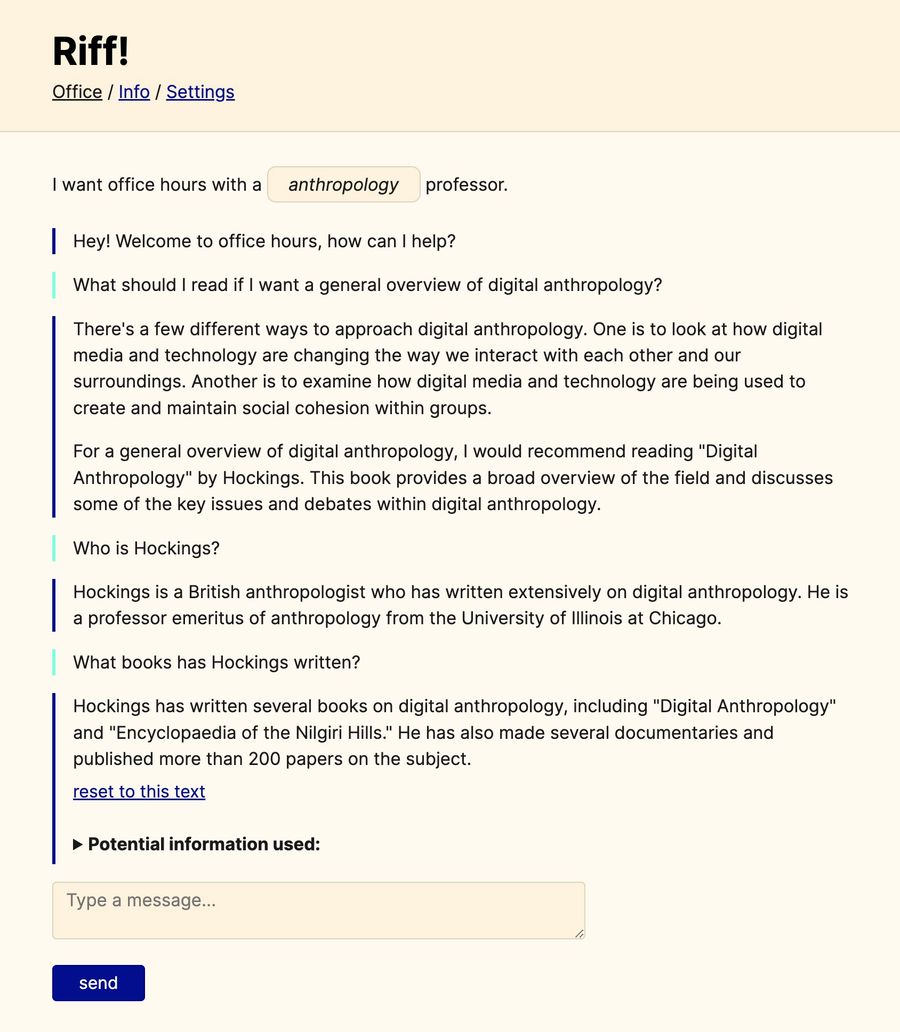
At first, this seems pretty good! The “Hockings” it’s telling me about is Paul Hockings , a real British anthropologist and professor emeritus at the University of Illinois. But he hasn’t done any work in digital anthropology, and certainly hasn’t written a book called “Digital Anthropology.” This blend of truth and fiction might be more dangerous than fiction alone. I might check one or two facts, find they’re right, and assume the rest is also valid.
Framing the model as a character in an informative conversation does help mitigate this though. It feels more like talking to a person – one you can easily talk back to, question, and challenge. When other people recite a fact or make a claim, we don’t automatically accept it as true. We question them. “How are you so sure?” “Where did you read that?” “Really?? Let me google it.” It is of course similarly problematic that the top ~3 results on Google are the arbiter of truth in our society, but we can’t pretend that’s not the current situation
Our model of humans is that they’re flawed pattern-matching machines that pick up impressions of the world from a wide variety of questionable and contradictory sources. We should assume the same about language models trained on questionable and contradictory text humans have published on the web.
There’s a different, and perhaps more troublesome, framing that I’m seeing pop up. Mainly from the slew of GPT-3 powered copywriting apps have been released over the last few months. This is language-model-as-insta-creator.
These writing apps want to help you pump out essays, emails, landing pages, and blog posts based on only a few bullet points and keywords. They do what I’m calling the approach where you type in a few key points, then click a big green button that “magically” generates a full ream of text for you.
Here’s an essay I “wrote” in Moonbeam by typing in the title “Chinese Economic Influence” and then proceeding to click a series of big green buttons:

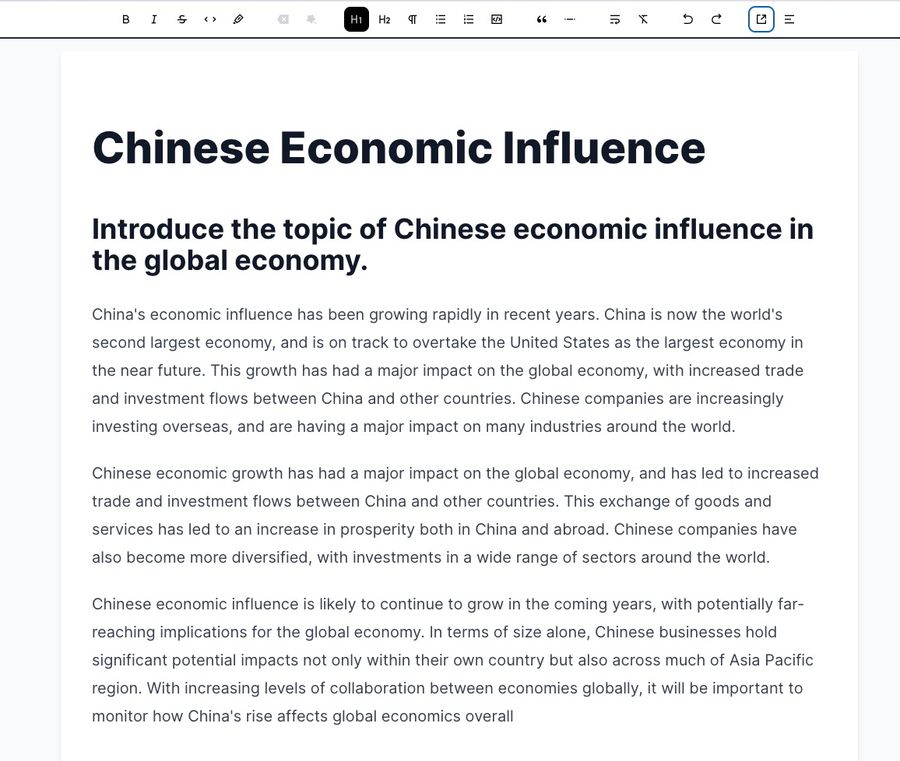
I know next to nothing about Chinese economic influence, so I’m certainly not the source of any of these claims. At first glance, the output looks quite impressive. On second glance you wonder if the statements it’s making are so sweeping and vague that they can’t really be fact-checked.
Who am I to say “Chinese economic influence is likely to continue to grow in the coming years, with potentially far-reaching implications for the global economy” isn’t a sound statement?
Here’s me putting the same level of input into Copy.ai , then relying on their “create content” button to do the rest of the work:
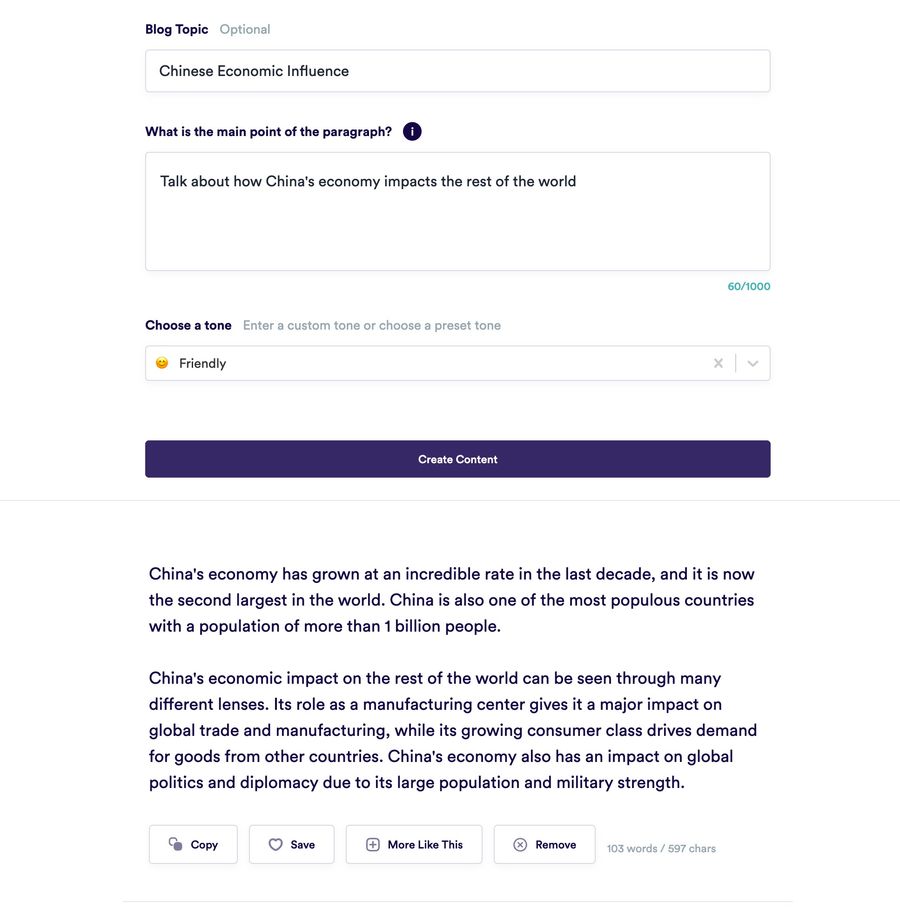
Again, the output seems sensible and coherent. But with no sources or references to back these statements up, what value do they have? Who believes these things about China’s economy? What information do they have access to? How do we know any of this is valid?
Disappointing Oracles
Our cultural narratives frame AIs as all-knowing oracles. The core problem is less that these models return outright falsehoods or misleading answers, but that we expect anything else from them. The decades-long cultural narrative we’ve been weaving about the all-knowing, dangerously super-intelligent machine that can absorb and resurface the collective wisdom of humanity has come back to bite us in the epistemic butt. Well-known figures in the industry speak about language models as oracles and journalists present them as magic . We’re currently in the awkward middle phase where we’re unsure how to calibrate future premonitions against current realities. We’ve come to expect omniscience from them too soon.

Three Failure States
There are three major problems with language models that shatter our vision of the all-knowing machine:
-
Trust is an all-or-nothing game.
If you can’t trust all of what a language model says, you can’t completely trust any of it. 90 correct answers out of 100 leave you with 10 outright falsities, but you have no way of knowing which ones. This might not matter too much for low-stakes personal queries like “should I invest in double-glazed windows?,” but becomes a deal-breaker for anything remotely more important. Legal, medical, political, engineering, and policy questions all need fail-safe answers. -
Models lack stable, situated knowledge.
One critical problem with language models we’re going to have to repeatedly reckon with is their lack of positionality. They don’t have fixed identities or social contexts in the way people do. Every conversation with a language model is a role-playing game. They take on characters based on the prompt. GPT-3 can pretend to be a squirrel in one moment, and not know what a squirrel is in the next.
There are ways we can use this to our advantage. If I tell GPT-3 it’s a great mathematician, it gets much better at maths! But this quality makes it especially troublesome to treat LLMs as sources of knowledge. Because all human knowledge is situated. It’s situated in times and places, in cultures, in histories, in social institutions, in disciplines, in specific identities, and in lived realities. There is no such thing as “the view from nowhere.” If you find this statement confusing, see all of postmodermism In this sense an LLM doesn’t “know” anything. It can’t present a consistent, coherent worldview in the way humans can. -
Our interfaces are black boxes
The people trying to use these models as sources of truth are not the ones at fault. They arrived at an interface that told them they could ask any questions they liked into the little text box, and it would respond with answers that sounded convincing and true. Plenty of them probably were true. But the interface presented few or no disclaimers, accuracy stats, or ways to investigate their answer. It didn’t explain how it arrived at that answer, or what data it used to get there. This is primarily because the creators of these interfaces and models don’t know how it arrives at an answer. Most language models are black boxes . It’s a bit complex to explain why but Grant Sanderson’s video series on how neural networks learn will help.
The problem isn’t the current state of GPTs. These models are developing at an alarming rate. But we’re in the very early days of generative transformers and large language models. GPT-3 came out in 2020. We’re 2 years into this experiment.
The lesson here is simply that until language models get a lot better, we have to exercise a lot of discernment and critical thinking. We need to stop using them to generate original thoughts, rather than help us reflect on our own thoughts.
Until we develop more robust language models and interfaces that are transparent about their reasoning and confidence level, we need to change our framing of them. We should not be thinking and talking about these systems as superintelligent, trustworthy oracles. At least, not right now.
We should instead think of them as epistemic rubber ducks.

Epistemic rubber ducking
Rubber ducking is the practice of having a friend or colleague sit and listen while you work through a problem. They aren’t there to tell you the solution to the problem or help actively solve it. They might prompt you with questions and occasionally make affirmational sounds. But their primary job is to help you solve their problem yourself. They’re like a rubber duck, quietly listening, while you talk yourself out of a hole.
The term comes from programming where you’re frequently faced with poorly defined problems that require a bit of thinking out loud. Originally coined from a story in The Pragmatic Programmer where one programmer carried around a literal rubber duck to talk through their code with Simply answering the question “what am I trying to do here?” is often enough to get started on a solution.
Language models are well suited to rubber ducking. Their mimicry makes them good reflective thinking partners, not independent sources of truth.
And not just any rubber ducking…
[decorate the text with floating rubber ducks and sparkles]
Epistemic rubber ducking
Epistemology is the study of how we know what we know, also called “theory of knowledge.” It deals with issues like how valid a claim is, how strong its claims and counter-arguments are, whether the evidence came from a reliable source, and whether cognitive biases might be warping our opinions.
Epistemic rubber ducking, then, is talking through an idea, claim, or opinion you hold, with a partner who helps you think through the epistemological dimensions of your thoughts. This isn’t simply a devil’s advocate incessantly pointing out all the ways you’re wrong. No one would tolerate that for long, which is why Effective Altruism is such an exhausting community to interact with.
A useful epistemic duck would need to be supportive and helpful. It would need to simply ask questions and suggest ideas, none of which you’re required to accept or integrate, but are there if you want them. It could certainly prod and critique, but in a way that helps you understand the other side of the coin, and realise the gaps and flaws in your arguments.
A collection of speculative prototypes
What would this look like in practice?
[Placeholder images for now - will make these video demos. Likely going to explore more tiny ideas to include]
Branches
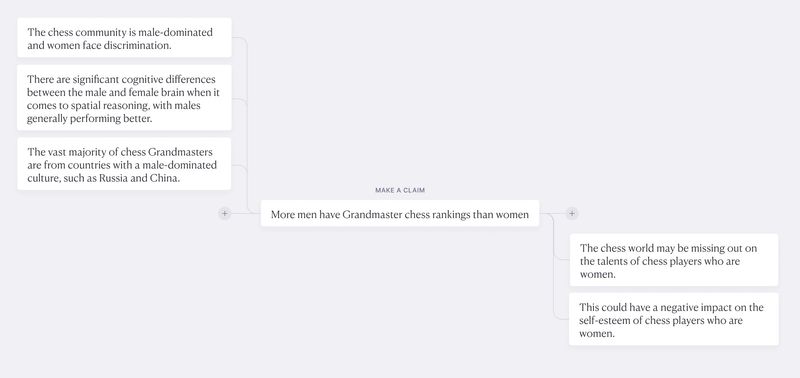
Argument maps
Daemons
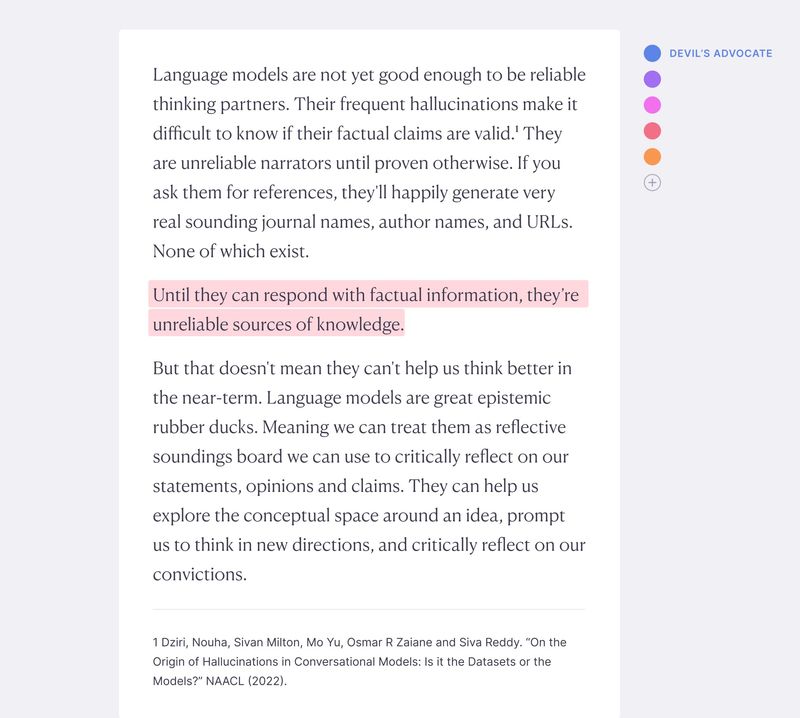
Epi
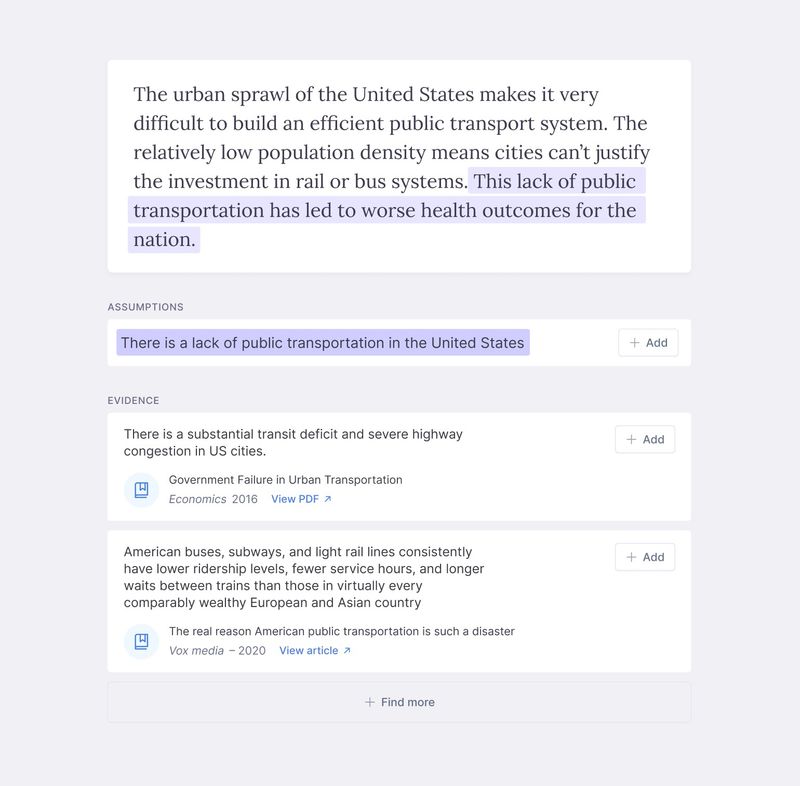
From anthropomorphism to animals
There’s a side quest I promised myself I wouldn’t go down in this piece, but I’ll briefly touch on it. I think we should take the duck-ness of language models as rubber ducks seriously. Meaning that conceiving of language models as ducks – an animal species with some capacity for intelligence – is currently better than conceiving of them as human-like agents.
I have very different expectations of a duck than I do of a human. I expect it can sense its environment and make decisions that keep it alive and happy and fat. I expect it has a more nuanced understanding of fish species and water currents and migration than I do. I don’t expect it would be a very competent babysitter or bus driver or physics teacher.
In short, the duck has very different intellectual and physical capacities from you or I. The same will be true of various “AI” systems like language models. Their form of “thinking” will certainly be more human-ish than duck-ish, but it would be a mistake to expect the same of them as we do of humans.
Kate Darling has made this argument around robots: that we should look to our history with animals as a touchstone for navigating our future with robots and AI.

An alternate analogy I’ve heard floating around is “aliens.” Many AI researchers talk about ML systems as a kind of alien intelligence. Given our cultural narratives around aliens as parasitic killers that are prone to exploding out of your chest, I’m pretty averse to the metaphor. Having an alien intelligence in my system sounds threatening. It certainly doesn’t sound like a helpful collaborative thinking partner. This might be a good thing if it helps motivate us to take AI alignment seriously.


I think there’s a lot more to explore here around the metaphors we use to talk about language models and AI systems, but I’ll save it for another post.
