Vibe code is legacy code
A lovely little write-up by my friend Steve Krouse on how vibe code and legacy code are roughly the same thing; “code that nobody understands.”
I particularly like this graph which illustrates the relationship between vibe code and understanding:
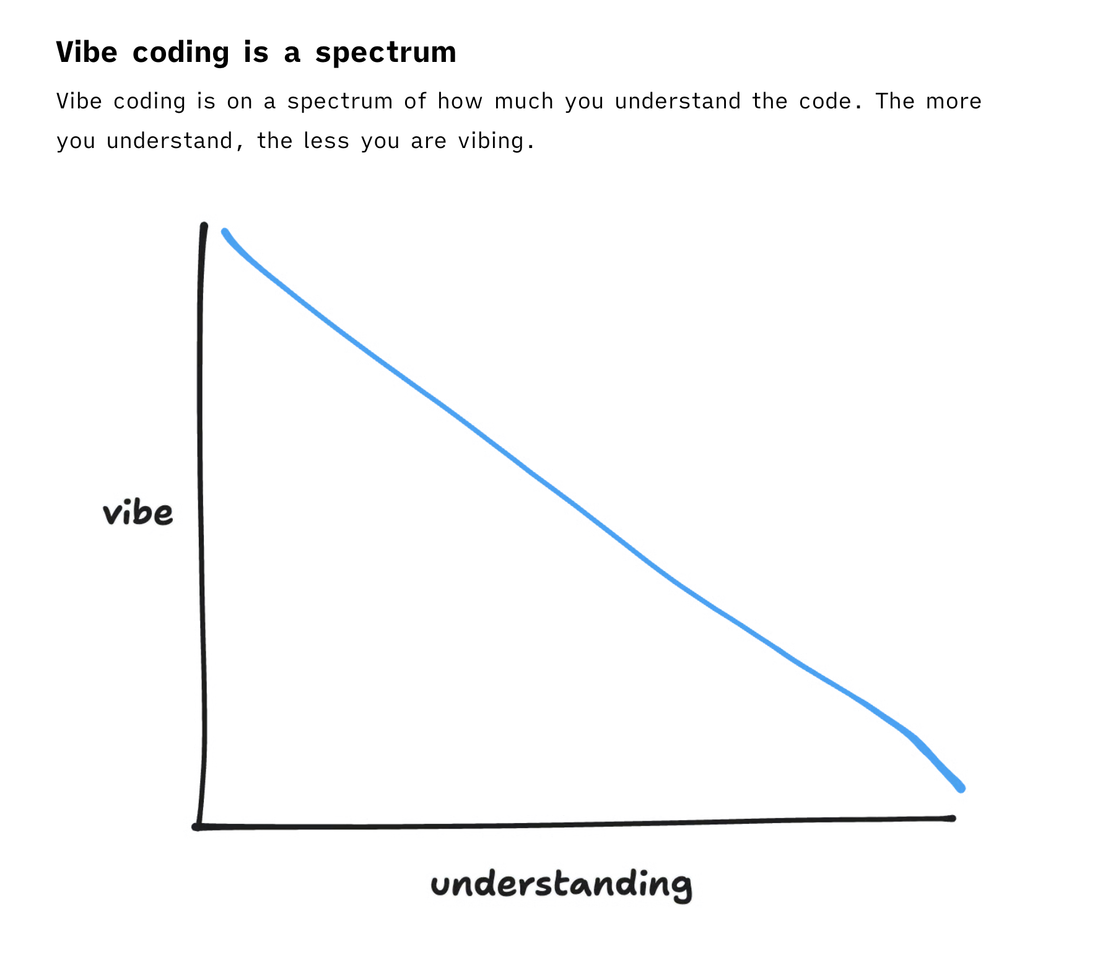
This type of discussion feels helpful in a moment where the term “vibe coding” is being tossed around in vague and unhelpful ways. It rings true to me that it’s a continuous spectrum, and no professional developers are sitting at the all-vibes end of it.
As many have pointed out , not all code written with AI assistance is vibe code. Per the original definition , it’s code written in contexts where you “forget that the code even exists.” Or as the fairly fleshed-out Wikipedia article puts it: ”A key part of the definition of vibe coding is that the user accepts code without full understanding.”
Like many developers, I’m constantly grappling with how much understanding I’m willing to hand over to Cursor or Claude Code. I sincerely try to keep it minimal, or at least have them walk me through the functionality line-by-line if I feel I’m out of my depth. But it’s always easier and faster to YOLO it – an impulse I have to actively keep in check.
Our AI minions are also exceptional tools for learning when you move too far towards the high-vibes-low-understanding end of the spectrum. I particularly like getting Claude to write me targeted exercises to practice new concepts when I get lost in generated functions or fail to implement something correctly sans-AI. Even though doubling-down up on engineering skills sometimes feels like learning to operate a textile loom in 1820.